Paper里记录了Bricklayers看论文过程中的笔记,由于bricklayer们性格各异,阅读习惯不同,研究方向不同,大家就看自己感兴趣的内容吧😊
最下面有分类的tag,可以根据感兴趣的tag看对应内容
Paper里记录了Bricklayers看论文过程中的笔记,由于bricklayer们性格各异,阅读习惯不同,研究方向不同,大家就看自己感兴趣的内容吧😊
最下面有分类的tag,可以根据感兴趣的tag看对应内容

Authors: Krizhevsky, Alex Sutskever, Ilya Hinton, Geoffrey E.
DOI: https://doi.org/10.1145/3065386
Year: 2017
期刊杂志: ILSVR2012 Champion, NIPS2012
Open Source: https://github.com/machrisaa/tensorflow-vgg 非官方
Future: 解决video上的有监督学习问题
Meaning: 在无监督学习的大环境中,用大数据的有监督学习一举击败无监督,开辟彩虹大道
ImageNet Classification with Deep Convolutional Neural Network
ImageNet:当时最大的图片分类数据集,100w图片 1000类别Deep Convolutional:卷积神经网络工作原理是什么? 同时作者为什么要使用 深度的卷积神经网络。2012 convolution 没有tree SVM🔥Neural Networks :神经网络,这篇文章使用了神经网络技术。
干了什么?
训练了一个large and deep的CNN,来分类120w图片的1000个类别
效果如何?
比前人工作好
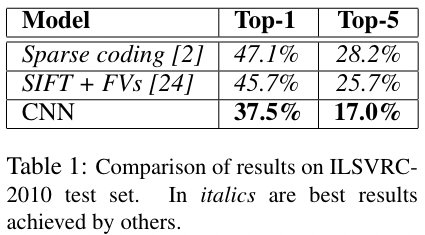
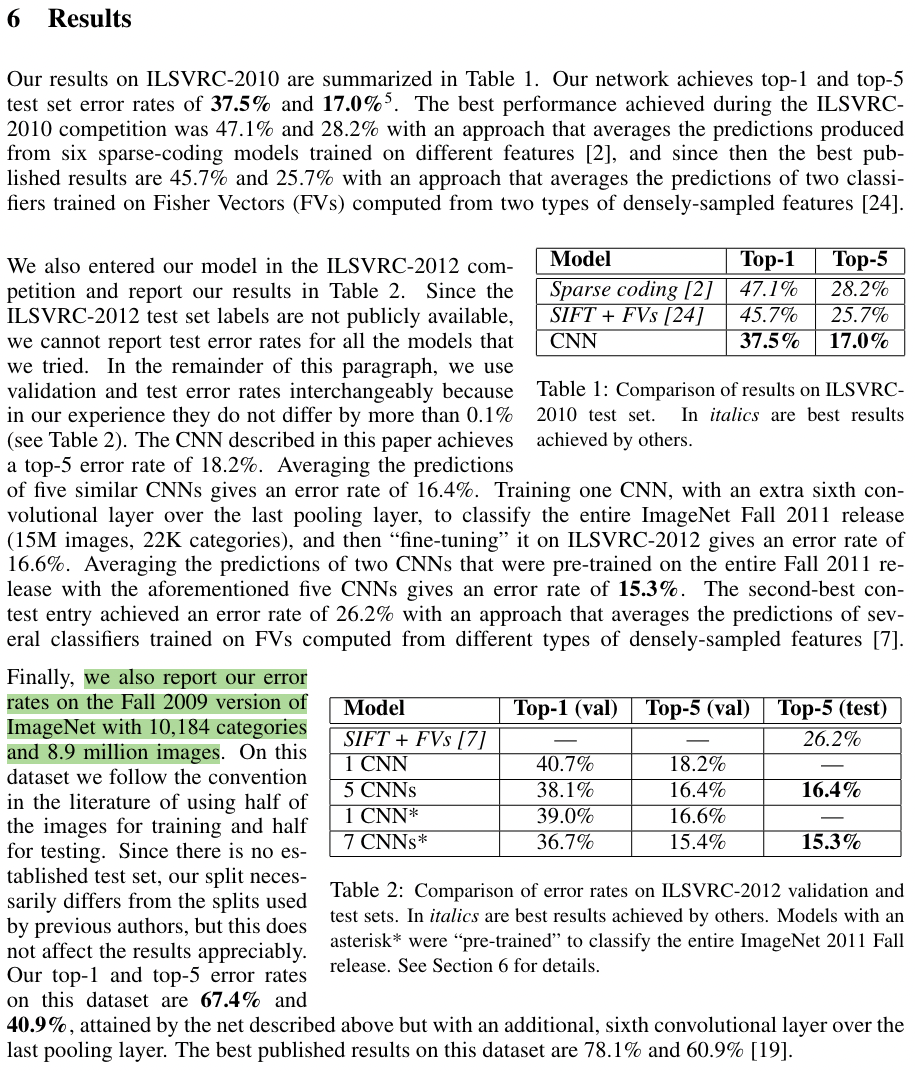
top-1 error: 37.5%
top-5 error: 17.0%
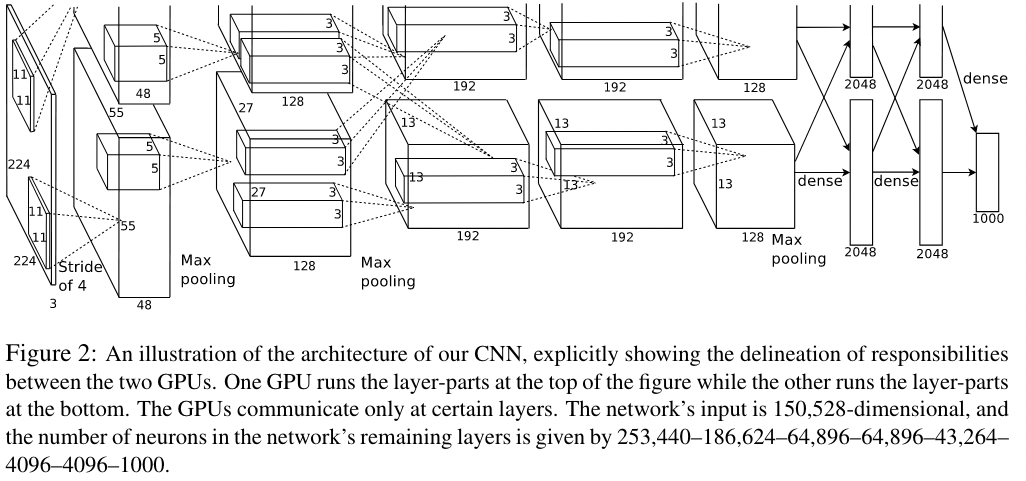
网络结构模样?
600w参数 65w神经元
5个卷积层(<5 max-pooling层)+ 3个全连接层(1000-way softmax)
参数太多,提高训练速度?
non-saturating neurons + GPU实现卷积运算
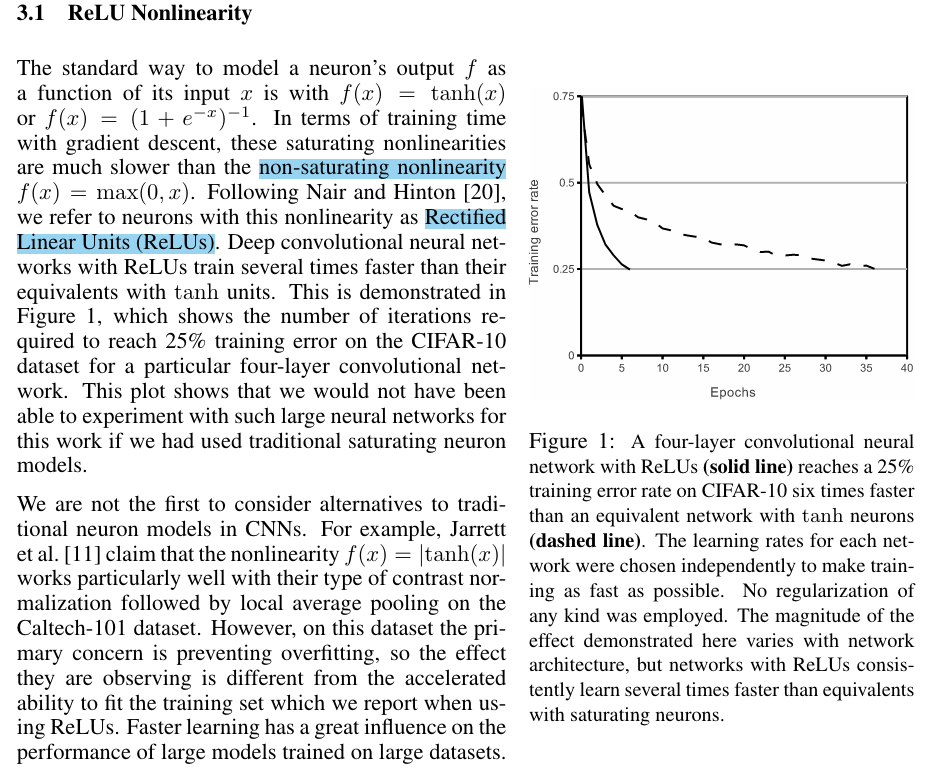
什么是non-saturating neurons非饱和神经元?
参数太多,过拟合了怎么办?
避免FCN的过拟合,dropout正则effective
为什么我这么厉害?
不告诉你,反正我是ILSVRC-2012的🏆,错误率比🥈低了10.9%

无conclusion和Abstract一一对应,只有discussion(吐槽) and future
一句话,怎么总结我的好?
a large, deep convolutional neural network is capable of achieving record-breaking results (SOTA) on a highly challenging dataset(指的是ImageNet)using purely supervised learning.
什么情况,我会表现的不好呢?
remove a single convolutional layer
i.e.,去掉中间层,降2%
Depth is important
深度重要,但深度是最重要的吗?
去掉一层convolutional layer, 降低2%,不能证明深度是最重要的
可能的情况:没设置好参数
AlexNet可以去掉一些层,调节中间参数,效果不变。直接砍掉一层,掉2%可能是搜索参数做的不够,没调好参数
反过来讲,结论没问题?
深宽都重要,i.e.,照片的高宽比
深度重要 → CNN需要很深
宽度也重要 → 特别深 + 特别窄 or 特别浅 + 特别宽 ❌
我们没有做什么?
did not use any unsupervised pre-training
不用unsupervised pre-training 也没关系?
2012年的DL的目的是:像”人“(不一定知道真实答案) 书读百遍 其义自现
通过训练一个非常大的神经网络,在没有标签的数据上,把数据的内在结构抽出来
关注的潮流怎么改变?
AlexNet之前大佬们爱:无监督学习
(Why dalao们不喜欢 有监督学习?)
(因为有监督学习打不过 树 SVM 😊)
AlexNet 证明大力出奇迹,模型够大,有标签数据够多,我🏆
最近大家一起爱:BERT、GAN
我们认为pre-training为什么好?
有充足计算资源可以增加网络size时,无需增加标注数据
我们有多牛?
我们可以通过 让网络变大,训练更久,变得更强
但2012年的结果 和人类比还是有差距的
Note: 现在图片里找简单的物品,DL比人类好很多,图片识别在无人驾驶的应用
我们怎么继续🐮呢?
在video上训练very large and deep CNN, 因为video里的时序信息可以辅助理解图片中的空间信息
这么牛的事情,大家做到了吗?
目前,video还是很难。why? 图片和语言进展不错,video 相对于图片的计算量大幅增加,video的版权问题

结果测试展示:
效果在比较难的case表现不错

motor scooter、leopard雪豹、grille敞篷车 ✅
cherry ❌

向量集合:输入图片在CNN的倒数第二层的数,作为每个图片的语义向量
给定一张图片,返回和我向量相似的图片;结果靠谱,🌹、🐘、🎃、🐶 都差不多
本文最重要的是什么?real wow moment
Deep CNN训练的结果,图片最后向量(学到了一种嵌入表示)的语义表示特别好~!
相似的图片的向量会比较近,学到了一个非常好的特征;非常适合后面的ML,一个简单的softmax就能分类的很好!
学习嵌入表示,DL的一大强项
和当前最好的结果的对比:远远超过别人(卖点、wow moment、sexy point)
96个卷积核,学习不同模式

模型架构图
第一遍可能看不懂
第一遍能看懂什么图?
实验结果图,比较了解的方向的模型结构图。以后第一遍读论文,遇到比较新、开创性、看不懂的模型结构图,第一遍放下,后面再看
第一遍的印象:结果特别好、NN实现的、为什么好?怎么做的?
第一遍读完做什么?
要不要继续读?
不读:很好用的 视觉网络;研究无关,放弃
读:CV研究者,工作很好,赢了今年的比赛,明年大家都用这个模型打比赛,我不试试吗?hhhh
参考:沐神讲解
1⃣️ 第一段

2⃣️ 第二段
描述了怎么做神经网络,这里只介绍了CNN
写论文的时候 ,千万不要只说自己这个领域这个小方向大概怎么样,还要提到别的方向怎么样

3⃣️ 第三段
4⃣️ 第四段

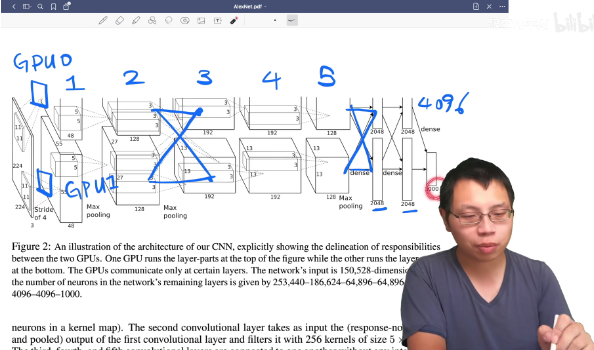
作者还强调了由于GPU内存的限制,在两块GPU上进行训练时需要5-6天时间,如果能有更快的GPU和更大的数据集,网络性能还能进一步提升

介绍了整个数据集大约有1500万张图片,共有22000类。ILSVRC比赛共有1000类,每一类大约有1000张图片。在2010的比赛中,可以得到测试集数据标签,但是在2012年的比赛中则没有测试集标签
由于ImageNet数据集图片精度并不相同,因此我们每一张图片下采样到256 × 256。当短边尺寸小于256时,我们先上采样到256,然后再从图片中截取 256 × 256的图片作为输入。我们没有对图片进行任何的预处理,整个网络是在每个像素的原始RGB值进行训练(也就是端到端训练,这也是深度学习的一大优势)

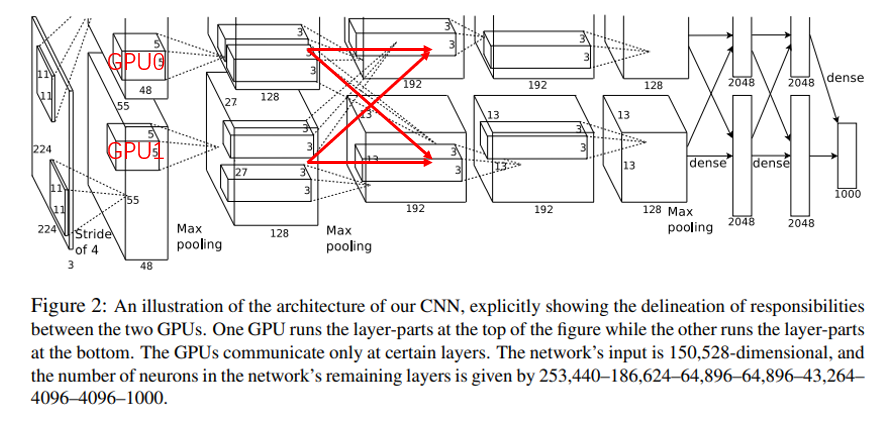
3.2 使用了多GPU进行训练

3.3 正则化、归一化

3.4 Overlapping Pooling

3.5 Overall Architecture


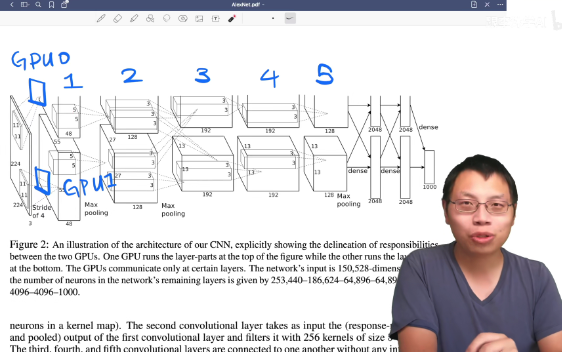
数据增强(data augmentation)


Dropout

讲述了模型是如何训练

下面是论文实验结果部分,可以看到在 ILSVRC-2010/2012数据上作者都取得了最低的错误率,同时作者也在2009年版本的 ImageNet全部数据上进行了训练,不过在 ImageNet全部数据集上进行训练的研究比较少
作者在训练时也发现了一些有意思的现象,就是两个GPU,一个GPU上和卷积核和图像颜色是有关的,一个和图像颜色是无关的,这个还待解释。另一个是图4所示,当最后一个隐藏层(4096)神经元欧几里得空间距离相近是,两张图片基本上是同一类(深度学习的解释性也是一个很重要的研究方向)

